转:
一. 前言
前面我们推荐了适合于MCU平台的压缩库minilzo, 我们这一篇继续来分享个类似的项目fastLZ。
fastLZ项目见
二. fastLZ特点
fastLZ是一个小型的可移植的字节对齐的LZ77压缩库。
该库有以下特点:
MIT许可。
ANSI C/C90实现的Lempel-Ziv 77算(LZ77)的无损数据压缩。
适用于压缩文本/段落序列、原始像素数据序列或具有大量重复的任何其他数据块。但是不打算用于图像、视频和其他通常已经以{BANNED}最佳佳压缩形式存在的格式的数据。
FastLZ的重点是非常快速的压缩和解压缩,这样做的代价是损失一些压缩比。
压缩enwik8时与zlib的比较如下:
|
|
Ratio
|
Compression
|
Decompression
|
|
FastLZ
|
54.2%
|
159 MB/s
|
305 MB/s
|
|
zlib -1
|
42.3%
|
50 MB/s
|
184 MB/s
|
|
zlib -9
|
36.5%
|
11 MB/s
|
185 MB/s
|
可以看到fastLZ如其名字重点在fast,适合对实时要求高于压缩比要求的应用场景。
FastLZ已经被许多软件产品所使用,从许多游戏的(如《Death Stranding》)到各种开源项目(Godot Engine, Facebook HHVM, Apache Traffic Server, Calligra Office, OSv, Netty等)。甚至可以作为其他压缩项目(如blossom)的基础。
FastLZ可以直接用于任何C/ c++应用程序。对于其他编程语言/环境,使用相应的绑定。Rust,Python,JavaScript,Ruby,Lua.
FastLZ只包含两个文件:FastLZ .h和FastLZ .c。使用FastLZ,只需将这些文件添加到项目中。有关执行压缩和解压缩的API的详细信息,参见fastlz.h即可。
其他字节对齐LZ77的实现,可以参考LZ4、Snappy、Density、LZO、LZF、LZJB、LZRW等。
三. 块格式
了解下Block format有助于理解如何使用该库。
假设将一个字节数组(称为未压缩块)压缩为另一个字节数组(称为压缩块)。可以通过演示FastLZ如何解压缩块以检索原始未压缩块来理解压缩块中存储的内容。
块的前3位,即{BANNED}中国第一个字节的3个{BANNED}最佳高有效位,是块标记。当前,块标记决定用于生成压缩块的压缩级别。块的内容将根据压缩级别而变化。目前定义了以下两个级别。
|
|
|
Block tag
|
Compression level
|
|
0
|
Level 1
|
|
1
|
Level 2
|
3.1Block Format for Level 1
暂时只介绍块格式的等级1.
FastLZ Level 1实现LZ77压缩算法,采用8KB滑动窗口,{BANNED}最佳大匹配长度为264字节。
压缩块由一条或多条指令组成。每条指令以1字节操作码、2字节操作码或3字节操作码开始。
注意,压缩块中的{BANNED}中国第一个指令总是Literal run。
|
|
|
Instruction type
|
Opcode[0]
|
Opcode[1]
|
Opcode[2]
|
|
Literal run
|
000, L?-L?
|
-
|
-
|
|
Short match
|
M?-M?, R??-R?
|
R?-R?
|
-
|
|
Long match
|
111, R??-R?
|
M?-M?
|
R?-R?
|
3.1.1Literal run 字面值指令
Literal run指令,字面值指令, 后面跟一个或多个原始字面值字节。
操作码[0]的5个{BANNED}最佳低有效位L4~L0决定了操作码后面的字面值的字节数量。0表示1字节,1表示2字节。所以0~31可以表示字节范围1~32。 因为如果是0字节的就是没有数据没有必要记录所以是从1字节开始。
解压缩程序从opcode后面的{BANNED}中国第一个字节开始拷贝(L + 1)字节即可。
例如:如果压缩块是一个4字节的数组[0x02, 0x41, 0x42, 0x43],操作码是0x02,这意味着是一个3字节的字面值。然后,解压缩器将随后的3个字节([0x41, 0x42, 0x43])复制到输出缓冲区。输出缓冲区现在表示(原始的)未压缩块,即为[0x41, 0x42, 0x43]。
3.1.2Short match短匹配指令
opcode[0]的高三位, M2~M0, 表示匹配长度match length. 1 表示匹配3字节 , 2 表示匹配4字节. M2~M0范围是1~6(0表示Literal run,7表示Long match)表示匹配3~8字节。
opcode[0]接下来的5位R12~R8 和opcode[1]的8位R7~R0, 一共13位R12~R0, 表示参考偏移reference offset. 表示偏移范围是0~8191.
对应如下代码
M = opcode[0] >> 5;
R = 256 * (opcode[0] << 5) + opcode[1];
解压缩器从输出缓冲区中偏移R的位置开始拷贝(M+2)个字节。注意R是一个反向引用,即0的值对应于输出缓冲区中的{BANNED}最佳后一个字节,1是倒数第二个字节,依此类推。
例1:如果压缩块是一个由[0x03, 0x41, 0x42, 0x43, 0x44, 0x20, 0x02]组成的7字节数组,那么其中有两条指令。{BANNED}中国第一条指令是4字节的literal run(由于L = 3)。因此,解压缩程序将4个字节复制到输出缓冲区,得到[0x41, 0x42, 0x43, 0x44]。第二条指令是3字节的短匹配(从M = 1开始,即0x20 >> 5)和R=2的偏移量。因此,压缩器从{BANNED}最佳后一个位置返回2个字节,复制3个字节([0x42, 0x43, 0x44]),并将它们附加到输出缓冲区。输出缓冲区现在表示完整的压缩前数据,[0x41, 0x42, 0x43, 0x44, 0x42, 0x43, 0x44]。
示例2:如果压缩块是一个包含[0x00, 0x61, 0x40, 0x00]的4字节数组,那么其中有两条指令。{BANNED}中国第一条指令是literal run 1个字节(L = 0)。因此,解压缩程序将字节(0x61)复制到输出缓冲区。输出缓冲区现在变成[0x61]。第二条指令是4字节的短匹配(从M = 2开始,即0x40 >> 5)和偏移量0。因此,解压缩器从向后引用0(即0x61的位置)开始复制4个字节。输出缓冲区现在表示完整的压缩前数据,[0x61, 0x61, 0x61, 0x61, 0x61]。
3.1.3Long match 长匹配指令
Opcode[1]的值M决定匹配长度。0表示匹配9字节,1表示匹配10字节,以此类推。0~255表示匹配长度为9~264。
Opcode[0]的低5位和opcode[2]的8位R决定了参考偏移量。由于偏移量以13位编码,{BANNED}最佳小值为0,{BANNED}最佳大值为8191。
M = opcode[1];
R = 256 * (opcode[0] << 5) + opcode[2];
解压缩器从输出缓冲区中偏移R的位置开始拷贝(M+9)个字节。注意R是一个反向引用,即0的值对应于输出缓冲区中的{BANNED}最佳后一个字节,1对应于倒数第二个字节,以此类推。
例如:如果压缩块是一个4字节的数组[0x01, 0x44, 0x45, 0xE0, 0x01, 0x01],那么其中有两条指令。{BANNED}中国第一条指令是长度为2的literal run(因为L = 1)。因此,解压缩器将2字节的字面值([0x44, 0x45])复制到输出缓冲区。第二条指令是长匹配,匹配长度为10(从M = 1开始),偏移量为1。因此,解压缩器从向后引用1(即0x44的位置)开始复制10个字节。现在的输出缓冲区代表完整的压缩前的数据,[0x44, 0 x45 0 x44 0 x45, 0 x44 0 x45 0 x44 0 x45 0 x44 0 x45 0 x44 0 x45]。
3.1.4解压实现
从以上看到解压很简单,首先只需要通过高3位确认指令
0表示字面值literal run
1~6表示短匹配
7表示长匹配
然后再按照对应的指令解析即可。
下面代码是一个解压c实现(没有溢出检查)
void fastlz_level1_decompress(const uint8_t* input, int length, uint8_t* output) { int src = 0; int dest = 0; while (src < length) { int type = input[src] >> 5; if (type == 0) { /* literal run */ int run = 1 + input[src]; src = src + 1; while (run > 0) { output[dest] = input[src]; src = src + 1; dest = dest + 1; run = run - 1; } } else if (type < 7) { /* short match */ int ofs = 256 * (input[src] & 31) + input[src + 1]; int len = 2 + (input[src] >> 5); src = src + 2; int ref = dest - ofs - 1; while (len > 0) { output[dest] = output[ref]; ref = ref + 1; dest = dest + 1; len = len - 1; } } else { /* long match */ int ofs = 256 * (input[src] & 31) + input[src + 2]; int len = 9 + input[src + 1]; src = src + 3; int ref = dest - ofs - 1; while (len > 0) { output[dest] = output[ref]; ref = ref + 1; dest = dest + 1; len = len - 1; } } }}
四. 源码
接口见fastlz.h非常简单,只有一个压缩一个解压函数,可以说是{BANNED}最佳简单的库了。
int fastlz_compress_level(int level, const void* input, int length, void* output);
int fastlz_decompress(const void* input, int length, void* output, int maxout);
五. 测试
添加文件fastlz.c/h到自己的工程。
添加测试代码fastlz_test.c如下
uint8_t in_data[64]={0x01,0x02,0x03,0x01,0x02,0x03,0x00,0x00,0x00,0x00,0x00,0xFF,0xFF,0xFF,0xFF,0xFF,0x01,0x02,0x03,0x01,0x02,0x03,0x00,0x01,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,0xFF,};uint8_t c_data[128];uint8_t d_data[128];int fastlz_test(int argc, char* argv[]);int fastlz_test(int argc, char* argv[]){ (void)argc; (void)argv; size_t len; int dlen; len = fastlz_compress_level(1, in_data, sizeof(in_data), c_data); if(len > sizeof(in_data)) { printf("in_data can not be compressed \r\n"); }else{ printf("compresse %d bytes to %d bytes\r\n",sizeof(in_data),len); } dlen = fastlz_decompress(c_data, len, d_data, sizeof(d_data)); if(dlen == 0) { printf("decompress err\r\n"); }else{ printf("decompresse %d bytes to %d bytes\r\n",len,dlen); } for(size_t i=0; i<sizeof(in_data);i++){ if(in_data[i] != d_data[i]){ printf("err pos %d %x!=%x\r\n",i,in_data[i],d_data[i]); } } return 0;}
测试打印如下

六. 资源消耗
6.1RAM需求
输入数据{BANNED}最佳小16字节
压缩数据输出空间要比输入空间大5%{BANNED}最佳低66字节。
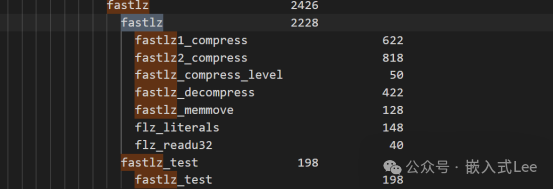
6.2Text需求
对于Text只需要2KB左右
6.3栈要求
函数中定义了数组需要8KB
uint32_t htab[HASH_SIZE];
#define HASH_LOG 13
#define HASH_SIZE (1 << HASH_LOG)
可以将其改为static或者使用动态内存分配
七. 总结
Fastlz的使用非常简单非常适合直接代码嵌入到自己的应用中。程序占用大概2KB,RAM大概需要8KB(默认是栈中,即hash表使用,可以改为全局或者动态分配)。